
This article will describe main architectural best practices in the cloud context and it is an interesting step to design cloud applications:
1. Multi-tier architecture
A simple three-tier architecture consists of a Presentation Tier (UI), an application or business Tier (Logic), and a Data Tier (database). We implement these tiers using web servers, application servers, and databases, respectively.
This tiered architecture on the cloud supports auto scaling and load balancing of web servers and application servers. Further, it also implements a master-slave database model across two different zones or data centers. The master database is synchronously replicated to the slave. Overall, the architecture represents a simple way to achieve a highly scalable and highly available application in a cloud environment.
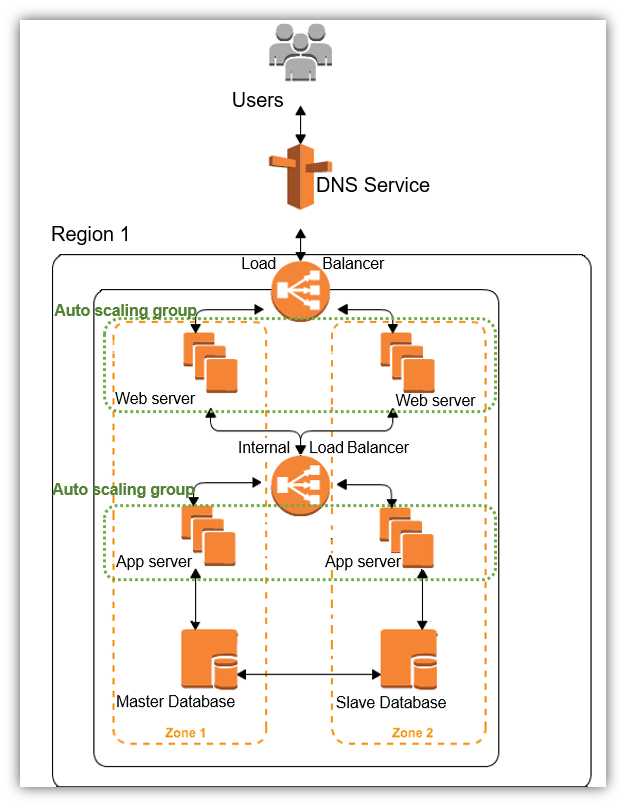
It is also possible to separate the tiers across two different regions in order to provide higher level of redundancy for our cloud applications design .
2. Designing for multi-tenancy:
The major benefit of multi-tenancy is cost saving due to infrastructure sharing and the operational efficiency of managing a single instance of the application across multiple customers or tenants. However, multi-tenancy introduces complexity. Issues can arise when a tenant’s action or usage affects the performance and availability of
the application for other tenants on the shared infrastructure. In addition, security, customization, upgrades, recovery, and many more requirements of one tenant can create issues for other tenants as well.
Multi tenant is cheap, whereas dedicated tenant is expensive, as it reserves for you the hardware, this case can be use especially for security reasons or to be aligned with some regulations.
3. Data security:
Organizational policies or regulatory requirements can mandate securing your data at rest. There are several options available from the cloud service provider and third-party vendors for implementing encryption to
protect your data. These range from manual ones implemented on the client-side to fully automated solutions.
Regardless of the approach, it is a good practice to encrypt sensitive data fields in your cloud database and storage. Encryption ensures that the data remains secure, even if a non-authorized user accesses it.
In many cases, encrypting a database column that is part of an index can lead to full table scans. Hence, try not to encrypt everything in your database, as it can lead to poor performance. It is therefore important to carefully identify sensitive information fields in your database, and encrypt them more selectively.
This will result in the right balance between security and performance.
4. Design Cloud Applications for scale:
Traditionally, designing for scale is about sizing carefully your infrastructure for peak usage, and then adding a factor to handle variability in load. At some point when you reach a certain threshold on CPU, memory, disk or network bandwidth, you will repeat the exercise to handle increased loads and initiate a lengthy procurement and provisioning process. Depending on the application, this could mean a scale up (vertical scaling) with bigger servers or scale out (horizontal scaling) with more number of servers.
In cloud applications, it is easy to scale both vertically and horizontally. Additionally, the increase and the decrease in the number of nodes (in horizontal scalability) can be done automatically to improve resource utilization, and manage costs better.
5. Loosely coupled architecture:
Loose coupling allows you to distribute your components and scale them independently. In addition, loose coupling allows parts of your system to go down without bringing the whole system down. This can improve the overall availability of your application.
The most commonly used design approaches to implement loose coupling is to introduce queues between major processing components in your architecture.
Most PaaS cloud providers offer a queuing service that can be used to design for high concurrency and unusual spikes in load. In a high velocity data pipeline type application, the buffering capability of queues is leveraged to guard against data loss when a downstream processing component is unavailable, slow, or has failed.
The following diagram shows a high capacity data processing pipeline. Notice that queues are placed strategically between various processing components to help match the impedance between the inflows of data versus processing components’ speed:
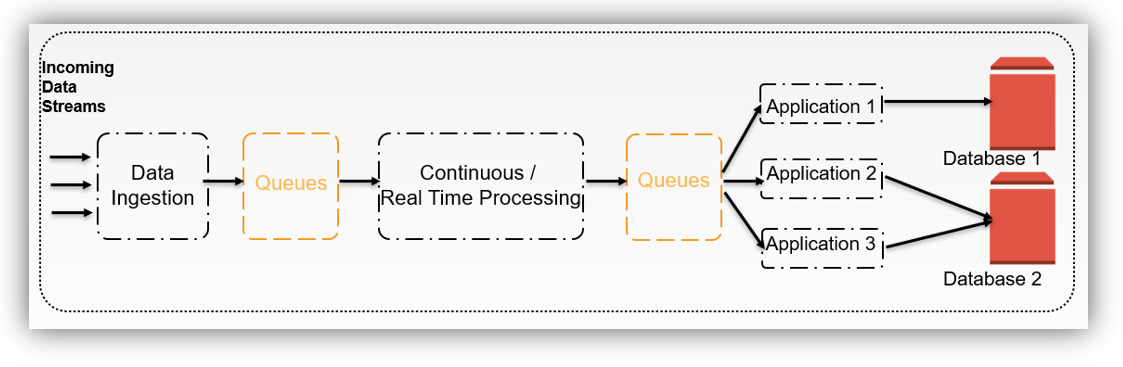
Typically, the web tier writes messages or work requests to a queue. A component from the services tier then picks up this request from the queue and processes it.
This ensures faster response times for end users as the queue-based asynchronous processing model does not block on responses.
6. Automating infrastructure:
During failures or spikes in load, you do not want to be provisioning resources, identifying and deploying the right version of the application, configuring parameters (for example, database connection strings), and so on. Hence, you need to invest in creating ready-to-launch machine images, centrally storing application configuration
parameters, and booting new instances quickly by bootstrapping your instances. In addition, you will need to continuously monitor your system metrics to dynamically take actions such as auto scaling.
It is possible to automate almost everything on the cloud platform via APIs and scripts, and you should attempt to do so. This includes typical operations, deployments, automatic recovery actions against alerts, scaling, and so on.
There are several tools and systems available from Amazon and other third-party providers that can help you automate your infrastructure. These include OpsWorks, Puppet, Chef, Docker..
7. Design Cloud Applications for failure:
Ensure you carefully review every aspect of your cloud architecture and design for failure scenarios: assume hardware will fail, cloud data center outages will happen, database failure or performance degradation will occur and so on.
The following are a list of key design principles that will help you handle failures in the cloud more effectively:
- Do not store application state or session on your servers, because if server fails, the application will stop responding.
- Logging should always be to a centralized location, for example, using a database or a third-party logging service.
- Your log records should contain additional cloud-specific information to help the debugging process: instance ID, region, availability zone…
- Avoid single points of failure. Plan to distribute your services across multiple regions and zones, and also implement a robust failover strategy. This will minimize the chances of an application outage due to individual instances, availability zone, or region.
8. Design Cloud Applications for parallel processing
It is a lot easier to design for parallelization on the cloud platform. You need to design for concurrency throughout your architecture, from data ingestion to its processing. So use multithreading to parallelize your cloud service requests, distribute load using load balancing, ensure multiple processing components or service endpoints are available via horizontal scaling, and so on.
As a best practice, you should exploit both multithreading and multi-node processing features in your designs. For example, using multiple concurrent threads for fetching objects from a cloud data storage service is a lot faster than fetching them sequentially.
9. Design Cloud Applications for performance
We can improve the user experience by reducing the perceived and real latency. For example: using memory optimized instances, right sizing your infrastructure, using caching, and placing your application and data closer
to your end users.
We reduce perceived latency by caching frequently used pages/data.
Ensure that the data required by your processing components are located as close to each other as possible. Use caching and edge locations to distribute static data as close to your end users as possible. Performance oriented applications use in-memory application caches to improve scalability and performance by caching frequently accessed data. On the cloud, it is easy to create highly available caches and automatically scale them by using the appropriate caching service.
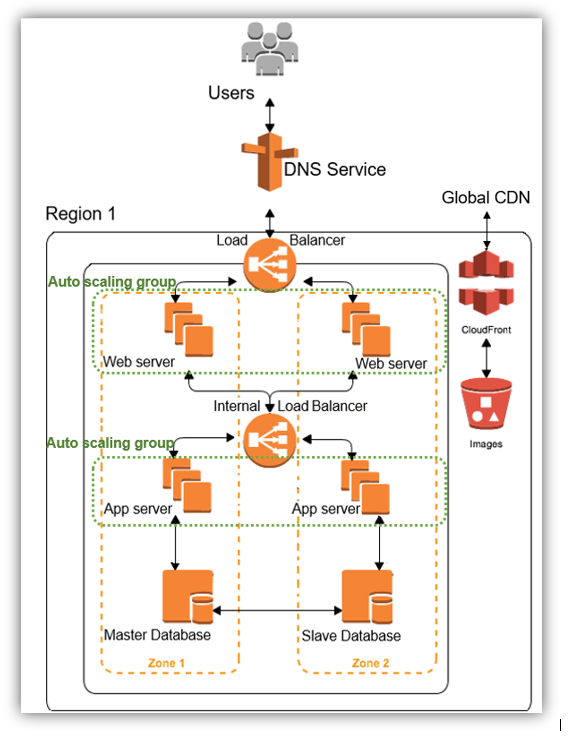
Most cloud providers maintain a distributed set of servers in multiple data centers around the globe. CDN (Content Delivery Network) machines serve content to end users from closest locations.
The following diagram shows how a typical web application hosted on the cloud can leverage the CDN service to place content closer to the end user. When an end user requests content using the domain name, the CDN service determines the best edge location to serve that content. If the edge location does not have a copy of the content requested, then the CDN service pulls a copy from the origin server (for example, the web servers in Zone 1). The content is also cached at the edge location to service any future requests for the same content:
10. Design Cloud Applications for eventual consistency
An application can tolerate a few seconds delay before the update is reflected across all replicas of the data. Eventual consistency can lead to better scalability and performance.
Normally, eventual consistency is the default behavior in a cloud data service. If the application requires consistent reads at all times, then some cloud data services provide the flexibility to specify strongly consistent reads. However, there are several cloud data services that support the eventually consistent option only.
Another approach used to improve performance is to deploy one or more read replicas close to your end users. This is typically used for read-heavy applications. The read traffic can be routed to these replicas to reduce latency. These replicas can also support resource-heavy queries for online report generation while your main database is down for maintenance.